Claude Fable 5: Ultimate Guide to Capabilities & Pricing

Claude Fable 5 is Anthropic’s first publicly available Mythos‑class model, offering frontier‑level reasoning, long‑context memory, and vision abilities while routing risky queries to a safer fallback. Launched on June 9 2026, it combines the raw power of the newer Mythos 5 engine with a layered safety system, making it the most capable model you can use today without special clearance.
What is Claude Fable 5 and why does it matter?
Claude Fable 5 sits in Anthropic’s Mythos‑class tier, a step above the Opus family. The model’s 1 million‑token context window and 128 k‑token output limit let it handle multi‑hour coding migrations, complex scientific analysis, and vision‑only tasks that earlier Claude models could not. Its release marks the first time a frontier model is offered to the general public, proving that high capability can coexist with a pragmatic safety approach.
Key facts:
- Release date: 9 June 2026
- Model string:
claude-fable-5(API) - Context window: 1 M tokens
- Pricing: $10 / M input tokens, $50 / M output tokens
Anthropic’s blog explains that the Mythos‑class “represents a capability threshold where misuse risk spikes” and therefore required a classifier‑driven fallback to keep public use safeanthropic.com.
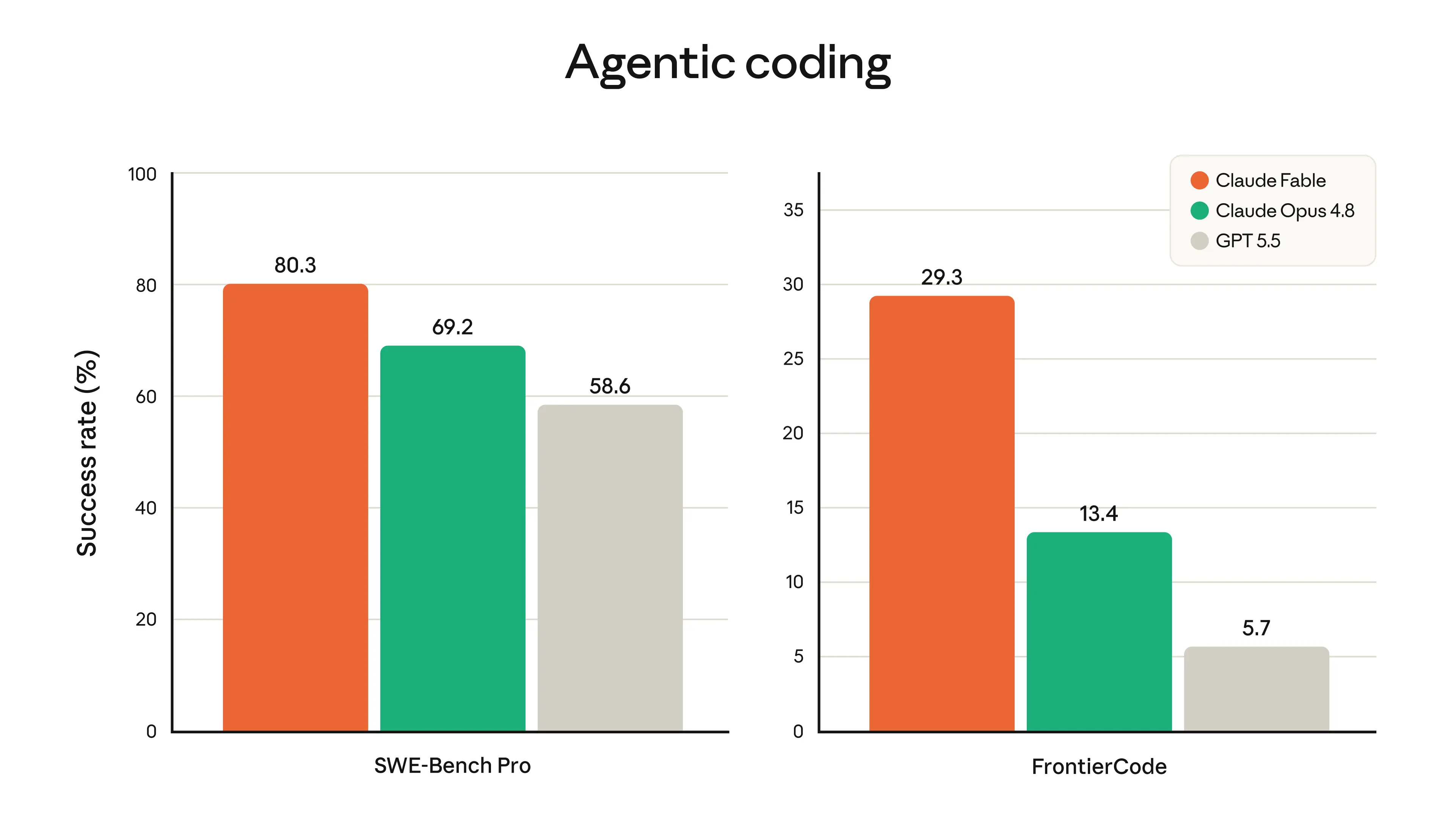 ## Key capabilities and benchmark highlights
## Key capabilities and benchmark highlights
Claude Fable 5 outperforms Opus 4.8 on every major frontier benchmark that early‑access partners have published.
- Software engineering – Stripe reported a 50‑million‑line Ruby migration completed in a single day, a task they estimated would take two months manually.
- Knowledge work – Hebbia’s Finance Benchmark gave Fable 5 the highest score for document‑based reasoning and multi‑step problem solving.
- Vision – The model extracted precise data from scientific figures and even beat Pokémon FireRed using a vision‑only harness, demonstrating unprecedented perception without custom scaffolding.
- Long‑context memory – In a Slay the Spire experiment, providing persistent file‑based notes boosted Fable 5’s performance three times more than Opus 4.8, proving superior use of external memory.
These results show a clear pattern: the larger the task horizon, the larger the gap between Claude Fable 5 and earlier models.
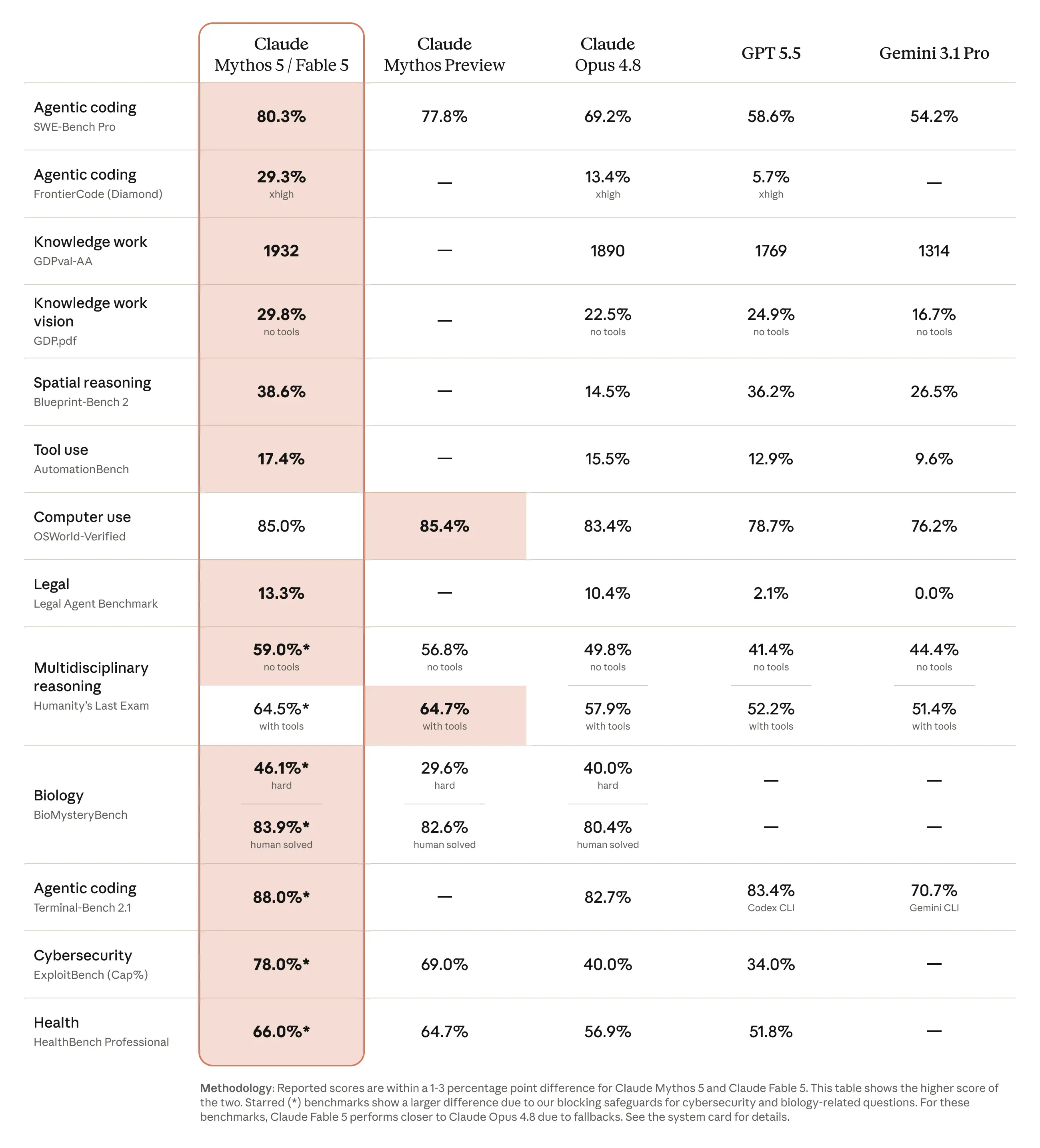 ## How does Claude Fable 5 compare to Claude Mythos 5 and Opus 4.8?
## How does Claude Fable 5 compare to Claude Mythos 5 and Opus 4.8?
All three models share the same underlying weights, but they differ in safeguard configuration and access level.
FeatureClaude Fable 5Claude Mythos 5Claude Opus 4.8TierMythos‑class (public)Mythos‑class (restricted)Opus‑class (public)Safety classifiersOn – routes cyber, bio, and distillation queries to Opus 4.8Off for vetted partners (cyber & bio unlocked)None needed (lower capability)Pricing$10 / M in, $50 / M out$10 / M in, $50 / M out$5 / M in, $25 / M outAvailabilityEverywhere (free window through 22 June)Glasswing partners & select researchersEverywhereTypical use caseLong‑horizon, high‑value tasksRestricted research, advanced cyber‑defenseRoutine work, latency‑sensitive jobs
In practice, 95 % of sessions never trigger a fallback, so Claude Fable 5 behaves identically to Mythos 5 for most users. When a classifier fires, the request is answered by Opus 4.8 rather than being refused, preserving utility while keeping risk low.
Pricing, availability, and how to get started
Claude Fable 5’s token rates are double those of Opus 4.8 but still less than half the price of the earlier Claude Mythos Preview. The model is accessible through:
- Claude web, desktop, and mobile apps on Pro/Max/Team plans (free inclusion until 22 June).
- Claude API using the model string
claude-fable-5.
If you need a concrete example of integrating the model into a product, try our AI Blog Writer tool at /tools/ai-blog-writer – it now supports Claude Fable 5 for long‑form, research‑heavy posts.
Quick cost calculator
Tokens processed Input cost Output cost Total
100 k input / 200 k output $1.00 $10.00 **$11.00**
1 M input / 2 M output $10.00 $100.00 **$110.00**
For most enterprise workloads, the higher per‑token price is offset by the model’s ability to finish complex jobs in fewer turns, often halving the total token consumption compared with Opus 4.8.
Safety classifiers and fallback mechanism
Claude Fable 5 ships with three dedicated classifiers:
- Cybersecurity – blocks or redirects queries that could aid offensive hacking.
- Biology & chemistry – routes potentially dual‑use scientific requests to Opus 4.8.
- Model distillation – prevents attempts to extract the model’s weights.
When any classifier flags a request, the system automatically falls back to Opus 4.8 and notifies the user. Anthropic’s internal testing shows this fallback occurs in < 5 % of sessions, and the fallback model still delivers high‑quality answers.
External red‑team testing (over 1 000 hours of bug‑bounty work) found no universal jailbreaks, and the cyber‑safeguard was rated the strongest among all models evaluated, according to TechCrunchtechcrunch.com.
When to choose Claude Fable 5 vs Opus 4.8
- Pick Claude Fable 5 for multi‑step code refactors, deep research, autonomous agents, or any task that benefits from a million‑token context. The capability boost often outweighs the higher price.
- Pick Opus 4.8 for high‑volume, latency‑critical, or cost‑sensitive workloads where frontier reasoning isn’t required. It also guarantees no fallback interruptions.
A practical pattern is to route routine queries to Opus 4.8 and escalate complex, long‑running jobs to Claude Fable 5. This hybrid approach balances cost, speed, and capability.
The broader impact
Claude Fable 5 demonstrates a new release philosophy: ship the most capable model once, then control risk through selective classifiers and a trusted‑access twin (Mythos 5). This “frontier model + safety wrapper” approach could become the industry standard for responsibly democratizing powerful AI.
All benchmark numbers are drawn from Anthropic’s public announcements and partner reports. Verify performance on your own data before committing to production.
Frequently asked questions
Claude Fable 5 is Anthropic's first publicly available Mythos‑class model, launched June 9 2026. It offers frontier reasoning, a 1 M token context window, and safety classifiers that route risky queries to Claude Opus 4.8.
Claude Mythos 5 uses the same weights as Fable 5 but has key safeguards lifted for vetted cyber‑defenders, infrastructure providers, and select researchers. Access is restricted through Anthropic’s Glasswing program.
Yes. They share identical training and weights. The only difference is the safety configuration: Fable 5 keeps classifiers active, while Mythos 5 runs with them disabled for approved users.
Fable 5 belongs to the higher‑capability Mythos‑class, excels at long‑horizon and vision tasks, and costs $10/$50 per million input/output tokens. Opus 4.8 is Opus‑class, cheaper ($5/$25), and serves as the fallback for Fable 5’s guarded queries.
$10 per million input tokens and $50 per million output tokens, which is double Opus 4.8’s rate but less than half the price of the earlier Claude Mythos Preview.
`claude-fable-5`.
Its classifiers detect requests involving cybersecurity, biology/chemistry, or model distillation and route them to Opus 4.8 to prevent misuse. This happens in fewer than 5 % of sessions, and users are notified when it occurs.
Anthropic’s alignment tests show low misalignment comparable to Opus 4.8. External red‑team testing found no universal jailbreaks after more than 1 000 hours of bug‑bounty work, and the cyber safeguard was rated the strongest among evaluated models.
Share this article
Send it to a teammate or save the link for later.
Related articles

Anthropic Mythos Is Back: Claude's Most Powerful AI
Anthropic's Claude Mythos AI is back with limited access for 100+ vetted institutions. What Mythos is, why it's restricted, pricing, and how to get access.
Read article
Free AI Tools to Use Now While Claude Fable 5 Is Down
Claude Fable 5 down? Use these free AI tools right now — no signup, no login. A practical roundup of free AI tools for writing, resumes, images, and OCR.
Read article
Anthropic AI pause: The Ultimate Guide to a Global AI Halt
Discover the Anthropic AI pause proposal, Claude code stats, verification hurdles, critiques, and how a global slowdown could reshape AI safety policy today.
Read article