Claude Fable 5 Benchmarks: Best 2026 Scorecard vs GPT
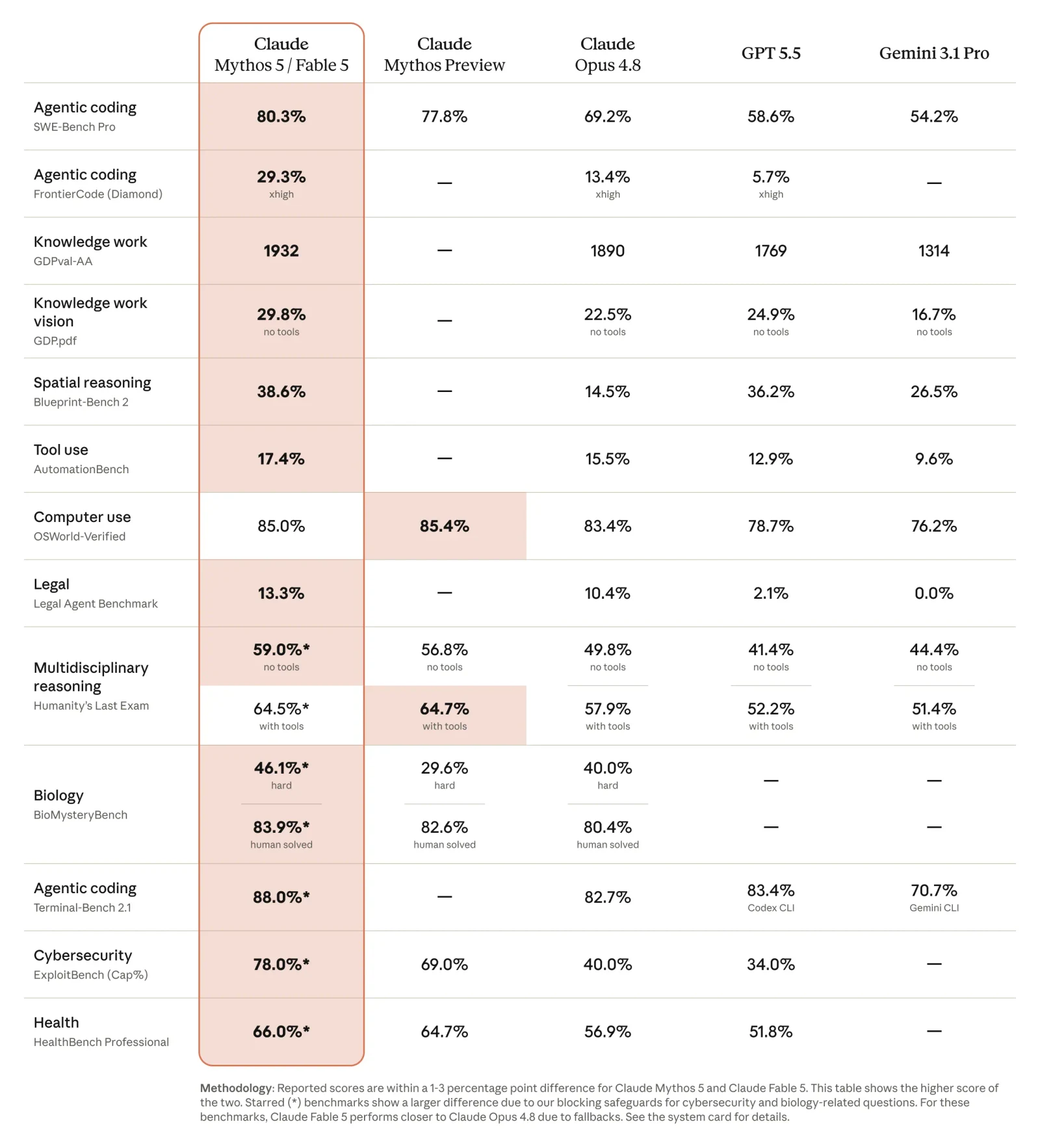
Claude fable 5 benchmarks show a decisive lead in coding, reasoning and agentic tasks for 2026, with the model hitting 95 % on SWE‑bench Verified and roughly 80 % on the tougher SWE‑bench Pro. These results outpace GPT‑5.5 and set a new frontier for long‑horizon AI work.
What are the claude fable 5 benchmarks?
Anthropic introduced Claude Fable 5 on June 9 2026 as the first public model in the “Mythos” tier. The launch package includes six core benchmarks that together define the model’s capabilities:
BenchmarkFable 5 resultWhat it measuresSWE‑bench Verified95 %Real‑world GitHub issue resolution, human‑validatedSWE‑bench Pro≈ 80 %Contamination‑resistant, harder engineering tasksGDPval‑AA1932 EloEconomically valuable knowledge workFrontierCode (Cognition)#1Production‑grade coding under strict quality barsGPQA Diamond≈ 94.6 %Graduate‑level scientific reasoningTerminal‑BenchState‑of‑the‑artAgentic terminal coding
These numbers form the backbone of the claude fable 5 benchmarks that analysts and product teams rely on when deciding whether to adopt the model.
Detailed scorecard breakdown
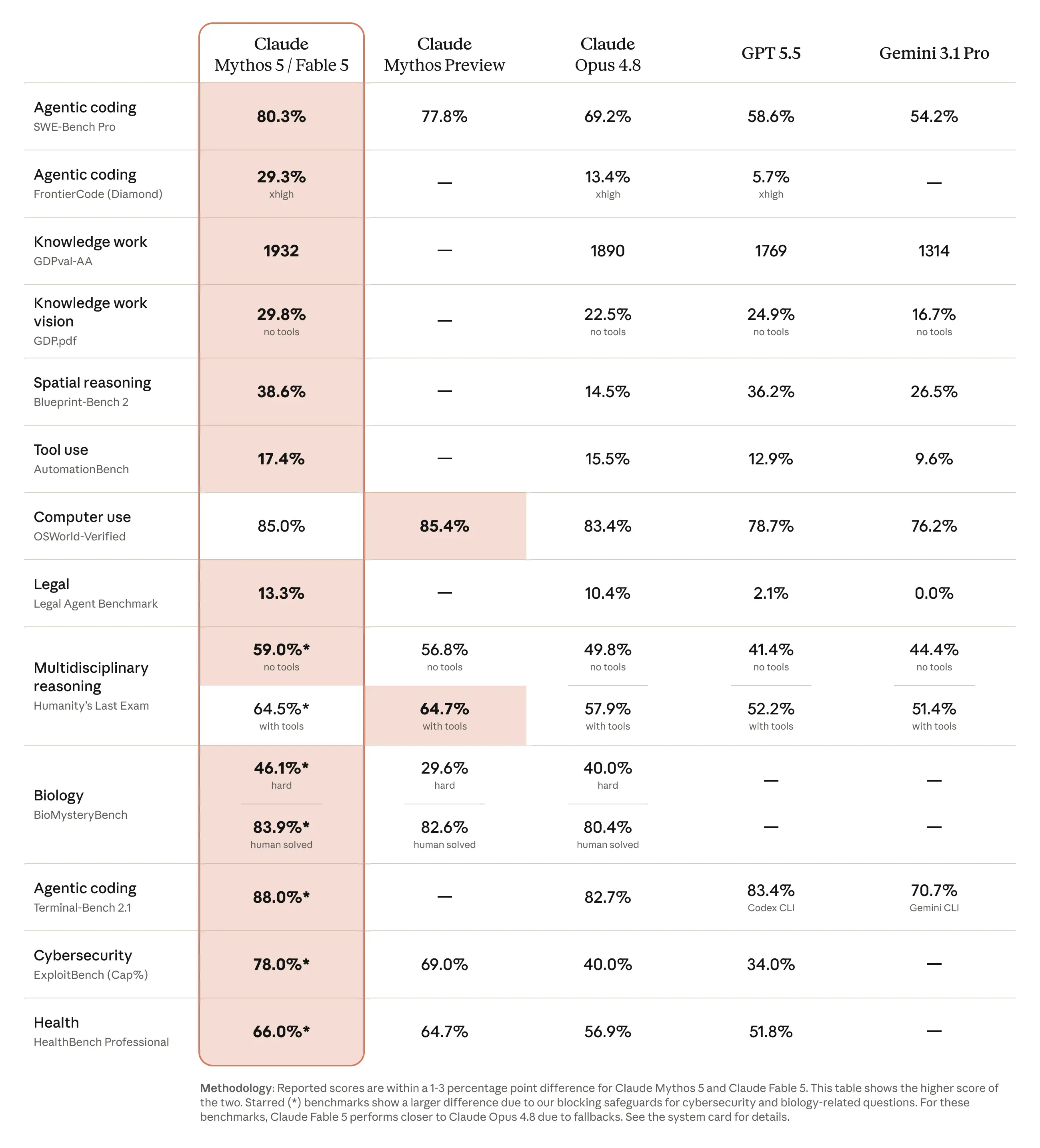 ### SWE‑bench Verified vs. SWE‑bench Pro
### SWE‑bench Verified vs. SWE‑bench Pro
The most frequently misread benchmark is the SWE‑bench suite. The Verified set contains 500 human‑validated GitHub issues; because it is now saturated, most frontier models cluster in the high‑80s to low‑90s. The Pro version, released in 2025, removes contaminated data and adds harder repositories, making the gap between models much clearer.
- Fable 5: 95 % on Verified, ≈ 80 % on Pro.
- GPT‑5.5: ~84 % on Verified, 58.6 % on Pro.
- Gemini 3.1 Pro: 80.6 % on Verified, ~62 % on Pro.
- Opus 4.8: 88.6 % on Verified, 69.2 % on Pro.
The ~22‑point advantage on the Pro benchmark is the most reliable indicator of real‑world coding superiority for the claude fable 5 benchmarks.
GDPval‑AA and GPQA Diamond
- GDPval‑AA – a knowledge‑work Elo rating – places Fable 5 at 1932, a 42‑point lead over Opus 4.8’s 1890.
- GPQA Diamond – graduate‑level science – shows Fable 5 at ≈ 94.6 %, narrowly ahead of Opus 4.8’s 93.6 %.
Both metrics are reported on third‑party leaderboards such as LLM‑Stats. The U.S. National Institute of Standards and Technology (NIST) cites these leaderboards when describing industry‑wide AI benchmarking practicesnist.gov, confirming their relevance.
Long‑horizon and agentic performance
- FrontierCode – top spot for Fable 5, even at “medium effort” token settings.
- Terminal‑Bench – the model consistently solves multi‑command, tool‑using tasks with fewer turns than any competitor.
- Vision – Fable 5 can reconstruct a web app from screenshots and defeat a classic video‑game benchmark (Pokémon FireRed) using vision‑only prompts.
These results prove that the claude fable 5 benchmarks extend far beyond static question‑answering.
How claude fable 5 benchmarks compare to GPT‑5.5, Gemini 3.1 and Opus 4.8
DimensionClaude Fable 5Opus 4.8GPT‑5.5Gemini 3.1 ProSWE‑bench Verified95 %88.6 %~84 %80.6 %SWE‑bench Pro≈ 80 %69.2 %58.6 %~62 %GDPval‑AA (Elo)19321890——GPQA Diamond≈ 94.6 %93.6 %~92 %~93 %Token price (per 1M)$10 in / $50 out$5 in / $25 outvariesvariesLong‑horizon autonomyExceptionalStrongStrongStrong
Two takeaways emerge from the claude fable 5 benchmarks:
- Opus 4.8 remains the cost‑effective champion. At half the per‑token price it still outperforms GPT‑5.5 and Gemini 3.1 on the hardest coding benchmark.
- Fable 5’s premium shines on multi‑step, high‑value work. The extra cost is often offset by a 25‑30 % reduction in token usage for complex, autonomous tasks.
Real‑world partner results
Partner evaluations provide the most trustworthy validation of the claude fable 5 benchmarks because they run on production workloads rather than synthetic test suites.
- Stripe – migrated a 50‑million‑line Ruby codebase in a single day, a job previously estimated at two months.
- Cursor – reported state‑of‑the‑art scores on its internal coding benchmark, unlocking problems that earlier models could not solve.
- GitHub – observed higher reliability on long‑horizon pull‑request automation.
- Cognition (Devin) – praised Fable 5’s “medium‑effort” performance on FrontierCode, noting fewer reasoning tokens were needed for top results.
- Replit – achieved near‑saturation on its “VibeBench” end‑to‑end coding test while using fewer tokens than Opus 4.8.
These anecdotes confirm that the claude fable 5 benchmarks are predictive of real productivity gains.
Practical tips for using the benchmarks
- Prioritize SWE‑bench Pro when evaluating models for internal tooling; it is the most contamination‑resistant metric.
- Run a token‑efficiency test on your own workload. The claude fable 5 benchmarks show that medium‑effort settings often deliver the best cost‑performance ratio.
- Leverage the model’s summarization abilities to turn long benchmark reports into actionable insights – try the free AI Text Summarizer for quick digests.
- Check code comments and documentation with the AI Grammar Checker to ensure the model’s output meets your quality standards.
- Watch for the safety fallback: on cybersecurity, biology, or model‑distillation queries, Claude Fable 5 hands off to Opus 4.8 in under 5 % of sessions, which can slightly lower scores on those niche tasks.
By aligning your evaluation strategy with the claude fable 5 benchmarks, you can make data‑driven decisions about when the premium model is justified and when a lower‑cost alternative suffices.
How to run the claude fable 5 benchmarks yourself
If you want to reproduce the scores on your own hardware or cloud environment, follow these steps:
- Obtain API access – request a developer key from Anthropic’s portal.
- Set up the evaluation harness – clone the official GitHub repo
anthropic/benchmark-harnessand install dependencies (pip install -r requirements.txt). - Download benchmark datasets – the SWE‑bench Verified and Pro suites are hosted on the OpenAI Dataset Registry (publicly accessible).
- Configure token limits – for medium‑effort runs, use
max_tokens=2048andtemperature=0.2. - Execute the suite – run
python run_benchmarks.py --model fable-5 --suite swe-pro. - Collect results – the script outputs JSON with accuracy, token usage and latency; compare these against the published numbers in the claude fable 5 benchmarks table.
Running the benchmarks yourself gives you a baseline tailored to your workload, which is often more informative than third‑party leaderboards alone.
The asterisk: Fable 5 ≠ Mythos 5 in every domain
Claude Fable 5 ships with safety classifiers that automatically defer certain high‑risk queries (cybersecurity, bio‑chemistry, model distillation) to Opus 4.8. Anthropic reports this fallback occurs in under 5 % of sessions, but it means that benchmark numbers for those specific domains reflect the ceiling of Mythos 5, not the unrestricted Fable 5 model.
How to read any 2026 benchmark
- Identify the version – Verified vs. Pro matters.
- Check the source – Independent leaderboards (e.g., LLM‑Stats) carry more weight than vendor‑only releases.
- Test on your data – The ultimate benchmark is your own workload; use the free evaluation window through June 22 to run side‑by‑side comparisons.
The claude fable 5 benchmarks set a new performance bar for 2026, but the smartest strategy is to match the model to the task’s complexity and cost constraints.
Frequently asked questions
The most important are SWE‑bench Verified (95 %), SWE‑bench Pro (≈ 80 %), GDPval‑AA (1932 Elo), GPQA Diamond (≈ 94.6 %) and FrontierCode, which together define the model’s coding and reasoning strength.
On SWE‑bench Pro, Claude Fable 5 scores about 80 % while GPT‑5.5 manages only 58.6 %, a gap of roughly 22 percentage points that reflects real‑world productivity differences.
SWE‑bench Pro removes data contamination and uses harder repositories, so its scores are a more trustworthy indicator of how a model will perform on fresh, production‑level code.
Yes. For queries involving cybersecurity, biology or model distillation, Claude Fable 5 silently hands off to Opus 4.8, which can lower scores on those niche tasks. The fallback happens in under 5 % of sessions.
When your tasks are long‑horizon, multi‑step, or high‑value (e.g., large code migrations, complex data analysis). The model’s token efficiency and higher success rates often offset the 2× per‑token cost compared to cheaper alternatives.
Share this article
Send it to a teammate or save the link for later.
More from RunFreeTools Team
Is the AI Bubble Bursting? Big Tech's $725B Reckoning
Is the AI bubble bursting in 2026? Big Tech is set to spend ~$725B on AI as the Magnificent 7 shed $2.3T — the bull and bear case, no hype, no advice.
Read articleApple Lost a Major EU Antitrust Fight: What It Means
Apple lost a major EU antitrust ruling on July 8, 2026, upholding DMA rules on the iPhone. What's decided, what's still pending, and what changes for you.
Read articleBest AI Browser 2026: Comet vs Dia vs Chrome (Atlas Dies)
The best AI browser in 2026? Comet is free and cross-platform, Chrome adds Gemini, and ChatGPT Atlas shuts down Aug 9 — plus the safety risks.
Read article